Linux内核模块
一:创建内核模块
lsmod //列出当前加载的所有内核模块
//这个命令会采用三列来列出当前的内核模块:名称、大小和正在使用的模块
modinfo simple.ko //获得模块的信息
//simple.c
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/module.h>
//printk是等价于printf的内核函数,然而它的输出被发送到一个内核日志缓冲区,其内容可以通过dmesg命令来读取。printk()与printf()之间的一个区别是:printk()允许指定一个优先级,具体值由文件<linux/printk.h>来定义。在这里,优先级为KERN_INFO,表示这是一个信息性(informational)消息
int simple_init(void){
printk(KERN_INFO "start\n");
return 0;
}
void simple_exit(void){
printk(KERN_INFO "end\n");
}
//下面两个宏用于向内核注册模块的入口点和退出点,都不能传递任何参数
//模块的入口点函数,当模块加载到内核时被调用
//返回0表示成功,其它表示失败
module_init(simple_init);
//模块的退出点,当模块从内核中移除时被调用
module_exit(simple_exit);
//下面三行说明软件许可、模块描述、作者等信息。对于我们而言,不会用到这些信息,但是我们包括它,因为这是开发内核模块的标准做法
MODULE_LICENSE("GPL");
MODULE_DESCRIPTION("Simple Module");
MODULE_AUTHOR("zzy");
这个内核模块simple.c的编译,可采用Makefile文件
//Makefile
KVERS = $(shell uname -r)
#shell中输出uname -r会获得内核版本号,这里将版本号存到变量KVERS
# Kernel modules
#将后面的东东编译为“内核模块”, obj-y 编译进内核,obj-n 不编译。
obj-m += hello.o
# 开启EXTRA_CFLAGS=-g-O0,可以得到包含调试信息的hello.ko模块。
#EXTRA_CFLAGS=-g -O0
#-C 表示让 make 命令进入指定的内核源代码目录
build: kernel_modules
kernel_modules:
make -C /lib/modules/$(KVERS)/build M=$(CURDIR) modules
clean:
make -C /lib/modules/$(KVERS)/build M=$(CURDIR) clean
输入以下命令行:
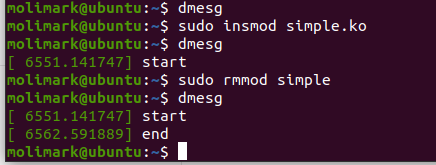
make //编译生成多个文件,文件simple.ko为已编译的内核模块。接下来的步骤用于将这个模块插入Linux内核
sudo insmod simple.ko //加载内核模块
lsmod //查看模块是否被加载
dmesg //检查内核日志缓冲区,检查模块是否已经加载
sudo rmmod simple //删除内核模块
sudo dmesg -c //由于内核日志缓冲区可能很快填满,通常最好定期清除缓冲区,可以这样进行
管道通信
Unix普通管道
父进程创建了一个管道,并写入数据,子进程读数据
#include <sys/types.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#define BUFFER_SIZE 25
#define READ_END 0
#define WRITE_END 1
int main(){
char write_msg[BUFFER_SIZE] = "Greetings";
char read_msg[BUFFER_SIZE];
// pipe(int fd[2]):创建一个管道,以便通过文件描述符int fd[]来访问;fd[0]为管道的读出端,而fd[1]为管道的写入端。UNIX将管道作为一种特殊类型的文件。因此,访问管道可以采用普通的系统调用read()和write()
int fd[2];
pid_t pid;
pipe(fd);
pid=fork();
if(pid>0){
close(fd[READ_END]);
write(fd[WRITE_END],write_msg,strlen(write_msg)+1);
close(fd[WRITE_END]);
}
else{
close(fd[WRITE_END]);
read(fd[READ_END],read_msg,strlen(read_msg)+1);
printf("%s\n",read_msg);
close(fd[READ_END]);
}
}
pthread多线程
pthread示例程序
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
int sum; // this data is shared by the thread(s)
void *runner(void *param); // threads call this function
int main(int argc,char *argv[]){
pthread_t tid; // the thread identifier
pthread_attr_t attr; // set of thread attributes
if(argc!=2){
fprintf(stderr,"usage: a.out <integer value>\n");
}
if(atoi(argv[1])<0){
fprintf(stderr,"%d must be >= 0\n",atoi(argv[1]));
}
// get the default attributes
pthread_attr_init(&attr);
// create the thread
pthread_create(&tid,&attr,runner,argv[1]);
// wait for the thread to exit
pthread_join(tid,NULL);
printf("sum = %d\n",sum);
return 0;
}
// The thread will begin control in this function
void *runner(void *param){
int i,upper = atoi(param);
sum=0;
for(i=1;i<=upper;i++)
sum+=i;
pthread_exit(0);
}
所有的Pthreads程序都要包括头文件pthread.h。语句pthread_t tid声明了创建线程的标识符。每个线程都有一组属性,包括堆栈大小和调度信息。声明pthread_attr_t attr表示线程属性;通过调用函数pthread_attr_init(&attr)可以设置这些属性。由于没有明确设置任何属性,所以使用缺省属性。通过调用函数pthread_create()可以创建一个单独线程。除了传递线程标识符和线程属性外,还要传递函数名称,这里为runner(),以便新线程可以开始执行这个函数。最后,还要传递由命令行参数argv[1]提供的整形参数。
在创建了累加和线程之后,父线程通过调用pthread_join()函数等待runner()线程的完成。累加和线程在调用了函数pthread_exit()之后就会终止。一旦累加和线程返回,父线程就输出累加和的值。
注:由于pthread不是Linux下的默认的库,也就是在链接的时候,无法找到phread库中哥函数的入口地址,于是链接会失败,因此在gcc编译的时候,要加 -lpthread参数
gcc pthread.c -o pthread -lphread
通过pthread_join()等待多个线程的一个简单方法:将这个操作包含在一个简单的for循环中。
#define NUM_THREADS 10
// an array of threads to be joined upon
pthread_t workers[NUM_THREADS];
for(int i=0;i<NUM>THREADS;i++){
pthread_join(workers[i],NULL);
}
多线程冲突案例
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
long long sum; // this data is shared by the thread(s)
void *runner(void *param); // threads call this function
int N = 100000;
int main(int argc,char *argv[]){
pthread_t tid1; // the thread identifier
pthread_t tid2;
pthread_attr_t attr1;
pthread_attr_t attr2;
pthread_attr_init(&attr2);
// get the default attributes
pthread_attr_init(&attr1);
// create the thread
pthread_create(&tid1,&attr1,runner,NULL);
pthread_create(&tid2,&attr2,runner,NULL);
// wait for the thread to exit
pthread_join(tid1,NULL);
pthread_join(tid2,NULL);
printf("sum = %lld\n",sum);
return 0;
}
void *runner(void *param){
for(int i=0;i<N;i++){
sum++;
}
pthread_exit(0);
}
输出:
sum = 131801
sum = 133510
sum = 105389
sum = 114163
sum = 161298
sum = 111119
sum = 119842
sum = 152644
而正确答案应该是:200000
多线程冲突案例解决方法(Peterson算法)
使用Peterson算法

#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#define BARRIER __sync_synchronize()
long long sum; // this data is shared by the thread(s)
void *runner1(void *param); // threads call this function
void *runner2(void *param);
int N = 30000000;
bool flagA=0;
bool flagB=0;
char door_flag;
int main(int argc,char *argv[]){
pthread_t tid1;
pthread_t tid2;
pthread_attr_t attr;
pthread_attr_init(&attr);
pthread_attr_t attr2;
pthread_attr_init(&attr2);
// create the thread
pthread_create(&tid1,&attr,runner1,NULL);
pthread_create(&tid2,&attr2,runner2,NULL);
pthread_join(tid1,NULL);
pthread_join(tid2,NULL);
printf("sum = %lld\n",sum);
return 0;
}
void *runner1(void *param){
for(int i=0;i<N;i++){
flagA=1;BARRIER; //保证flagA=1在door_flag='B'之前执行
door_flag='B';
while(door_flag=='B'&&flagB==1);
sum++;//BARRIER; 按照常理应该也要保证sum++在flagA之前执行,但不知道为什么这里不加BARRIER执行顺序也不会出错
flagA=0;
}
pthread_exit(0);
}
void *runner2(void *param){
for(int i=0;i<N;i++){
flagB=1;BARRIER;
door_flag='A';
while(door_flag=='A'&&flagA==1);
sum++;//BARRIER;
flagB=0;
}
}
通过全局变量读取另一个线程局部变量
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
void *runner1(void *param);
void *runner2(void *param); // threads call this function
int *tem;
int main(int argc,char *argv[]){
pthread_t tid1; // the thread identifier
pthread_t tid2;
pthread_attr_t attr1;
pthread_attr_t attr2;
pthread_attr_init(&attr2);
// get the default attributes
pthread_attr_init(&attr1);
// create the thread
int fa_tem = 0;
tem = &fa_tem;
printf("main's tem = %d\n",*tem);
pthread_create(&tid1,&attr1,runner1,NULL);
pthread_create(&tid2,&attr2,runner2,NULL);
pthread_join(tid1,NULL);
pthread_join(tid2,NULL);
return 0;
}
void *runner1(void *param){
int tem1 = 5;
tem = &tem1;
printf("runner1's tem = %d\n",*tem);
sleep(3);
pthread_exit(0);
}
void *runner2(void *param){
sleep(1);
printf("runner read runner1's local tem = %d\n",*tem);
pthread_exit(0);
}
输出结果:
main's tem = 0
runner1's tem = 5
runner read runner1's local tem = 5
自旋锁
自旋锁实现sum
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
long long sum;
void *runner1(void *param);
void *runner2(void *param);
int N = 300000;
int self_lock;
int xchg(volatile int *addr, int newval) {
int result;
asm volatile ("lock xchg %0, %1"
: "+m"(*addr), "=a"(result) : "1"(newval));
return result;
}
int main(int argc,char *argv[]){
pthread_t tid1;
pthread_t tid2;
pthread_attr_t attr;
pthread_attr_init(&attr);
pthread_attr_t attr2;
pthread_attr_init(&attr2);
pthread_create(&tid1,&attr,runner1,NULL);
pthread_create(&tid2,&attr2,runner2,NULL);
pthread_join(tid1,NULL);
pthread_join(tid2,NULL);
printf("sum = %lld\n",sum);
return 0;
}
void lock(){while(xchg(&self_lock,1));}
void unlock(){while(!xchg(&self_lock,0));}
void *runner1(void *param){
for(int i=0;i<N;i++){
lock();
sum++;
unlock();
}
pthread_exit(0);
}
void *runner2(void *param){
for(int i=0;i<N;i++){
lock();
sum++;
unlock();
}
pthread_exit(0);
}
输出:600000
自旋锁原理与缺陷
原理:一开始桌子上有一把钥匙,每个到来的线程都要拿自己的一个东西与桌子上的东西交换,只有拿到钥匙的人才能进入房间。出房间时将钥匙与桌子上的东西交换。
缺陷:
-
性能问题(0)
- 自旋(共享变量)会触发处理器间的缓存同步,延迟增加
-
性能问题(1)
- 除了进入临界区的线程,其他处理器上的线程都在空转
- 争抢锁的处理器越多,利用率越低
-
性能问题(2)
- 获得自旋锁的线程可能被操作系统切换出去,实现100%的资源浪费
Comments